V úterý zde na Lupě vyšel článek pana Kopty s názvem „Web ovládnou aplikace“. Rád bych na něj navázal a doplnil jej o další pohled na to, jaká je možná budoucnost části webu a především budoucí forma aplikací, které v něm budou provozovány. Řeč bude o specifické formě aplikací, pro které se vžilo označení „webové služby“, v angličtině „web services“. Co jsou vlastně zač a v čem se odlišují od těch aplikací, které jsou v rámci Internetu a na platformě webu používány dnes?
Chceme-li správně pochopit jejich podstatu a principy, je vhodné začít pohledem zpět – jak to vypadalo s provozováním aplikací dříve.
Monolitické aplikace
Nejstarší aplikace provozované ve světě počítačů měly monolitický charakter. To znamenalo, že byly vytvořeny jako jediný a dále nedělitelný celek („jeden kus“). Provozovat se daly a dodnes dají jak na samostatných počítačích (například na izolovaných PC), tak i na sdílených počítačích vybavených terminály.
V prostředí sítě, ať již lokální či rozlehlé (včetně Internetu), se dají používat také, a to v režimu host/terminál. Tradičně tyto monolitické aplikace běží na počítačích označovaných jako „hostitelské“ (host), a uživatelé vzdálených počítačů (v roli terminálů) k těmto aplikacím přistupují pomocí mechanismů vzdáleného přihlašování (v prostředí TCP/IP sítí např. skrze Telnet, případně rlogin).
Nověji byl tento model zdokonalen tak, že umožňuje provozovat i aplikace s grafickým výstupem (např. pomocí systému X Window, WinFrame či MS Terminal Server).
Aplikace rozdělené napůl
Dalším vývojovým stádiem bylo rozdělení původně monolitických aplikací na dvě samostatné části, neboli známý model klient/server. Snad jej není nutné podrobněji rozvádět, ale možná je vhodné zdůraznit jeden konkrétní aspekt: zatímco modelu host/terminál je víceméně jedno, zda pracuje na izolovaných počítačích s terminály či v síťovém prostředí (nebo dokonce v Internetu), model klient/server již se síťovým prostředím přímo počítá – když předpokládá, že klient i server budou provozováni na různých uzlech sítě, a mezi nimi bude existovat možnost komunikace.
Další významnou charakteristikou je těsná vazba mezi oběma částmi – klient i server, kteří dohromady tvoří nějakou aplikaci, jsou spolu svázáni zejména pravidly vzájemné komunikace, formáty předávaných dat (povelů, zpráv apod.). V praxi to znamená, že ke každé službě implementované v architektuře klient/server, musí být nejen specifické servery, ale také specifičtí klienti, uzpůsobení povaze příslušné aplikace. V prostředí původního Internetu to znamenalo, že pro každou konkrétní službu musel mít uživatel nainstalovaného příslušného klienta, musel se o něj starat, musel se naučit s ním pracovat, musel jej pravidelně aktualizovat atd. Pamětníci si možná ještě vzpomenou na vyhledávání pomocí klientů Archie či WAIS, na klienty WHOIS, na čtečky síťových News a další.
Třívrstvá architektura klient/server
Dnes již uživatelé Internetu nepotřebují samostatné klientské programy pro nejrůznější aplikace. Došlo totiž k tomu, že prakticky všechny „ostatní“ aplikace, původně samostatné, se přestěhovaly na platformu webu (případně elektronické pošty), staly se z nich jakési „nadstavby“ nad webem, a uživatelé s nimi pracují skrze své klientské programy pro web (tedy skrze své browsery).
Třeba když dnes něco hledáte na Internetu, už si ani nemusíte uvědomovat, že váš klient (browser) komunikuje s WWW serverem, za kterým je „schován“ další server, příslušející již specifické aplikaci – a právě on pak zajišťuje to, co je pro danou aplikaci vlastní a specifické (tzv. aplikační logiku). Sám pak má obvykle za sebou ještě další server, který pro něj řeší práci s daty (tzv. databázový server).
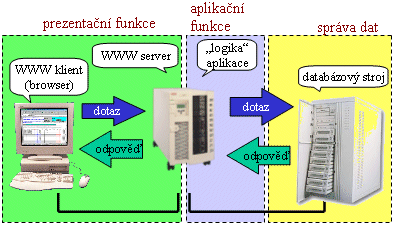 |
Přesně stejně je tomu i v případě, kdy například nakupujete po Internetu v některém z eshopů, když hledáte v jízdním řádu či v telefonním seznamu, když pracujete se svým účtem v bance prostřednictvím internetbankingu atd.
Hlavní předností takovéto třívrstvé architektury je skutečnost, že všem uživatelům stačí jediný klientský program (browser) pro práci s různými aplikacemi. Je to dáno tím, že tento browser realizuje pouze značně univerzální prezentační funkce, zatímco to, co je pro danou aplikaci specifické, realizuje aplikační server (který je jen jeden, stejně jako databázový server).
Co jsou webové služby?
Přeskočme nyní nepříliš úspěšné stádium tzv. network computingu, neboli éru tzv. tenkých klientů (kdy aplikace sice „sídlí“ v síti, ale pro svůj běh se stěhují na klientské počítače) a řekněme si rovnou, co že jsou ony v úvodu slibované webové služby.
Existuje samozřejmě celá řada různých definic webových služeb, ale většina z nich se shoduje v následujícím aspektu:
zatímco v případě (třívrstvé) architektury klient/server je výstup serveru určen browseru víceméně jen k zobrazení uživateli, v případě webové služby je určen spíše někomu jinému (jiné aplikaci), a spíše k dalšímu „logickému“ zpracování než k pouhému „mechanickému“ zobrazení.
Nebo ještě jinak: i v případě webové služby platí, že server poskytující určitou službu je pasivní a čeká, až jej někdo o něco požádá. Tím, kdo jej o něco žádá, však nyní už obvykle není browser řízený požadavky uživatele (nejspíše klikáním na odkazy v právě zobrazované stránce), ale nějaká jiná aplikace, plnící své specifické úkoly.
Představme si to na příkladu. Třeba taková vyhledávací služba Google dosud poskytovala své služby jenom skrze webové stránky – uživatel si načetl stránku s vyhledávacím formulářem, do něj zadal svůj dotaz a stránku odeslal. Zpět dostal odpověď od Googlu, opět v podobě WWW stránky. Tedy nějaký lineární seznam odkazů na WWW stránky. Pokud měl uživatel jinou představu o výsledku – třeba jej chtěl znázornit graficky, nebo nějak dále zpracovat, případně zkombinovat s jinými výsledky, musel si to zařídit sám. V případě webové služby může tento uživatel (nebo kdokoli jiný) vytvořit úplně jinou aplikaci, která si sama vyžádá příslušná data od služby Google jako své vstupy, zpracuje je podle svých potřeb, a s výsledkem naloží opět podle svých představ – například je uživateli zobrazí v grafické podobě místo v podobě seznamu apod.. Nebo může zrealizovat cokoli jiného, například nějaké hodně specializované vyhledávání, třeba i kombinované s prohledáváním dalších informačních zdrojů apod.. Už tomu začínáte rozumět?
Příklad se službou Google není zcela náhodný – právě Google totiž webovým službám vychází vstříc (podrobněji zde). Dokonce natolik, že dřívějším akademickým diskusím o budoucnosti webových služeb dává podstatně realističtější obrysy. Ostatně, sami provozovatelé Googlu byli překvapeni odezvou, kterou jejich vstřícný krok vyvolal:
Největším překvapením pro mne je to, že využití stále roste … bál jsem se, že to bude takové plácnutí do vody. Nejspíše to ale souvisí s tím, že lidé si teprve teď začínají uvědomovat, co vlastně jsou webové služby.
 |
Z dalších významných subjektů, poskytujících své služby na Internetu, se k podobnému kroku odhodlal také známý Amazon. I on nyní umožňuje, aby se mu jiné aplikace samy „hrabaly“ v jeho katalogu, vyhledávaly zde to, co potřebují a výsledky dále zpracovávaly podle svých představ a potřeb.
 |
Co je nutné k fungování webových služeb
Vrátíme-li se zpět k samotné podstatě webových služeb a představíme-li si je jako další vývojové stádium architektury klient/server, pak je možné konstatovat, že jde stále o řešení se dvěma hlavními částmi:
- klientem, který je nyní (na rozdíl od webového browseru) znovu samostatnou aplikací s vlastní inteligencí a vlastní logikou zpracování dat
- serverem, u kterého ale přestává být „zřetelná“ jeho fyzická podstata a vše se soustřeďuje na schopnost poskytovat určité definované služby. Proto se také v souvislosti s webovými službami někdy hovoří o modelu klient/služba, místo o modelu klient/server.
U webových služeb se dále významným způsobem změnil vztah mezi samotným klientem (aplikací) a službou (serverem poskytujícím službu). Zatímco dříve byly tyto dvě složky poměrně pevně svázány a jejich vazba měla statický charakter, v případě webových služeb je jejich vazba značně volnější a má dynamický charakter. Lze si představit, že aplikace (klienti) a služby budou ve stále větší míře existovat nezávisle na sobě, teprve na základě určité momentální potřeby se budou hledat a nacházet, a budou spolu (dynamicky) spolupracovat. K tomu je ovšem nutné vytvořit určité předpoklady a také je realizovat – prostřednictvím protokolů, standardů atd.
Základní představa je taková, že se popíše to, co jednotlivé služby nabízí, jak se s nimi komunikuje, a tyto informace se uloží do vhodných adresářů. Přes ně pak budou moci konkrétní aplikace (klienti) vyhledávat konkrétní služby a také je využívat. V první fázi se přitom počítá s tím, že aplikace (klienti) budou samy spíše statické povahy, ale do budoucna pravděpodobně dostanou schopnost autonomního pohybu v prostředí sítě, resp. Internetu. Pracuje se také již na konkrétních standardech, z nichž některé jsou k dispozici již dnes a další se připravují či dokončují, vylepšují atd. Jde např. o jazyk XML (pro formulaci požadavků a odpovědí na ně), SOAP (pro vzájemnou komunikaci), WSDL (pro popis webových služeb), UDDI (pro realizaci adresářů webových služeb) a další.

Stejně tak je nutné zvolit i vhodný ekonomický model pro poskytování webových služeb. Také ten dosud není příliš ustálen, ale v každém případě o něm lze již dnes říci, že bude moci být podstatně více zaměřen na zpoplatnění „podle skutečné konzumace“, než založen na tradičních modelech typu „podle počtu uživatelů“ či „podle počtu serverů“ apod.
Ale to vše by již bylo na podrobnější povídání ve formě samostatných článků.






































 ČLÁNKY DO MAILU
ČLÁNKY DO MAILU
{kind=link}